

Instant GPU clusters
Large scale, on-demand clusters on any infrastructure, our cloud or your own.
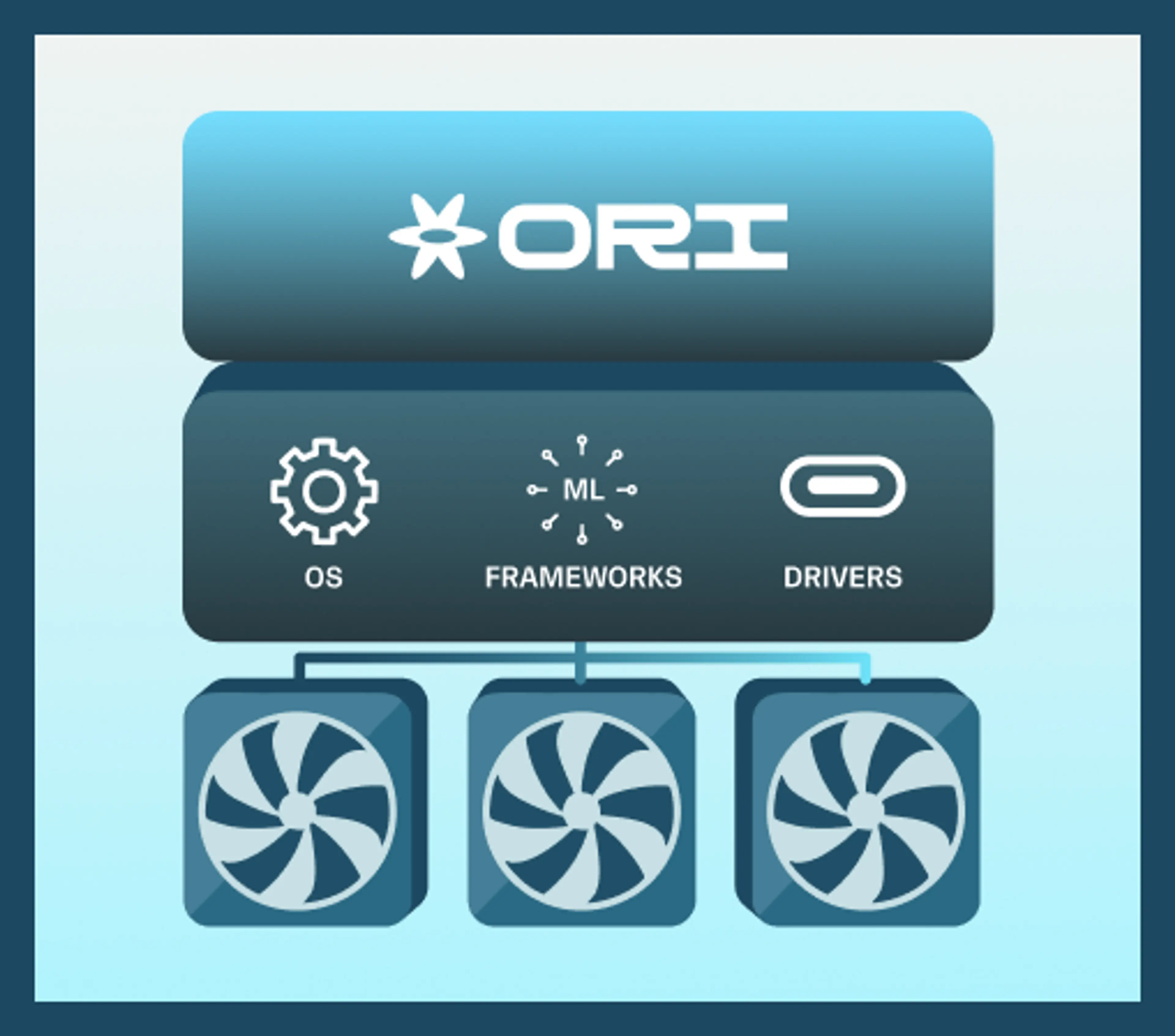
Combine hundreds or even thousands of best-in-class NVIDIA or AMD GPUs, all working together to train foundation models and run multi-client inference. No reservations or manual approval needed on Ori’s cloud and fully configurable on yours.
No more pre-paying for clusters and waiting for compute, storage and networking to be ready. Pay as you go and spin up GPU clusters in minutes.

Large scale, on-demand clusters on any infrastructure, our cloud or your own.

High-speed NVIDIA Infiniband or RoCE (RDMA over Converged Ethernet) to aggregate massive compute in real-time.

Fast and automated recovery of faulty nodes for maximum uptime.

GPU Direct to bypass CPU and enable efficient data transfer from storage and network interfaces to GPU memory.
The Ori team has a wealth of experience in building cutting-edge AI and HPC clusters that are in production across the world. From compute to storage and networking, supercomputers are designed to extract every ounce of performance, while our support team helps keep your training runs uninterrupted and maximize inference uptime.

Ori Supercomputers gave us the scale and performance of a custom-built GPU cluster without the time, cost, or complexity of managing one, enabling us to accelerate the training of our foundation models significantly.