

Pack more work on each GPU
Fractional sharing (MIG), secure segmentation, and node‑level bin‑packing put capacity to work instead of leaving it stranded.

Fractional sharing (MIG), secure segmentation, and node‑level bin‑packing put capacity to work instead of leaving it stranded.

A global control plane sees real‑time capacity and latency across sites and regions, then routes training and inference to the best location.

High‑throughput storage paths and data locality awareness keep accelerators fed, not waiting on I/O.

Autoscaling helps you expand coverage just in time and scale down to zero to reduce idle burn.
Train, fine‑tune, and serve on the same fleet without rewiring.
Enhance the experience for your customers.
Since idle and fragmentation drop across teams, regions, and tenants.
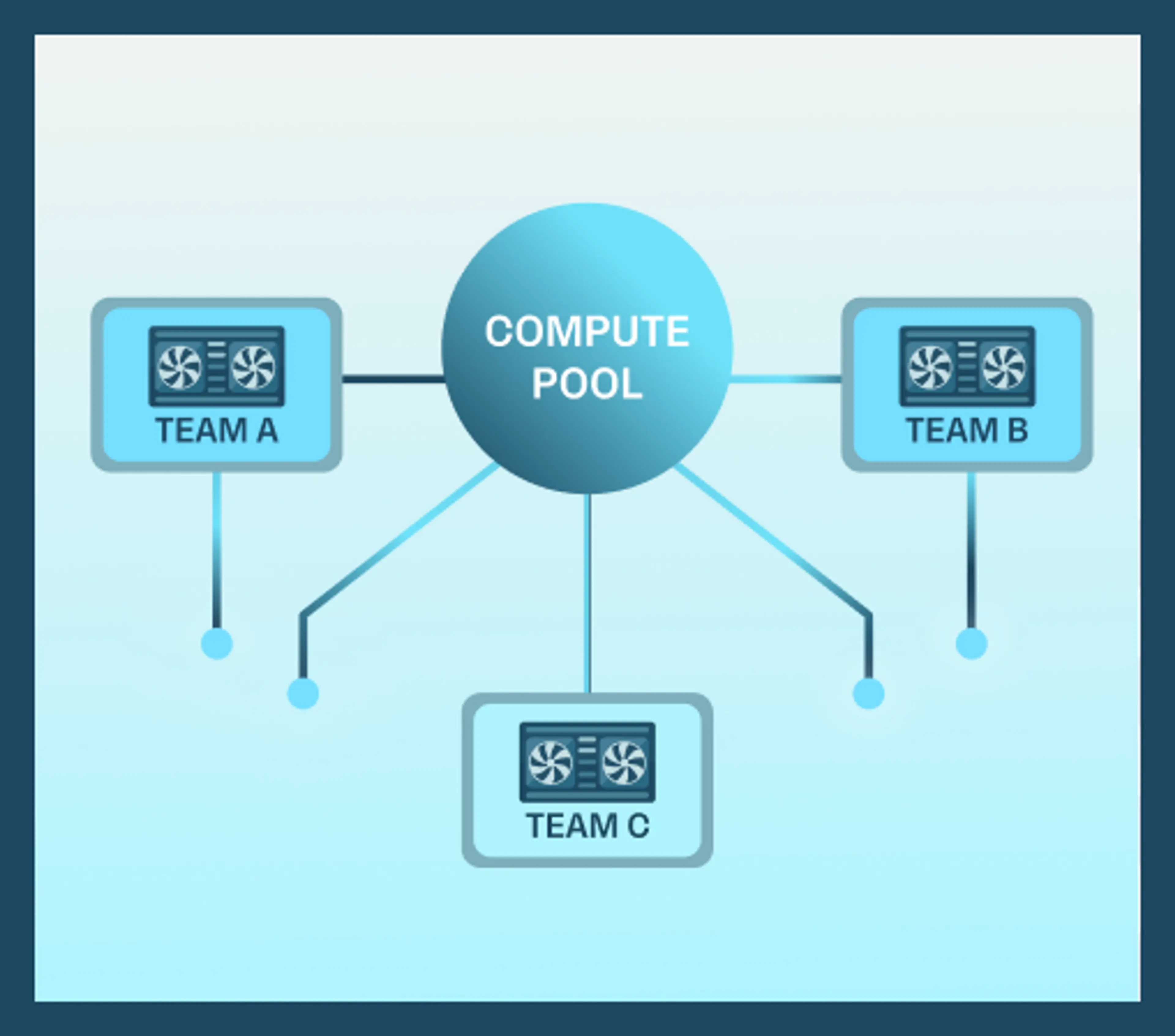
Consolidate GPUs and accelerators across teams and geographies into an optimized resource pool to maximize utilization.

Granular compute usage metrics, audit trails and service-level usage across locations, users and organizations.
Monitor and accurately bill customers or internal teams based on usage, by the minute.
Enable fair resource sharing among customers and teams, while supporting burst capacity when needed.